作品名称:你,或者你们,或者我们,或者我
创作时间:2008
展览: Shanghai eArts Festival 2008
展区:蓄与化——青年新媒体艺术作品展
展览时间:2008-10-18 ~ 2008-11-08
官方网站介绍页面:http://www.shearts.org/index.php/?p=591&lang=zh-cn (可能会失效)
介绍
该作品的理念介绍在官方网站的作品介绍页面中已经给出了,所以就不再介绍。
不过在展览期间,乃至后来,一直有人反映不明白作品需要表现什么含义,这里就简单的介绍下相关的过程:
该作品首先会实时监控某一网络(1000台计算机以上规模)中的数据通讯,从中截取并捕捉到用户在各种搜索引擎上的关键词信息。并在展会现场将这些关键词加以处理和呈现。
至于其中的理念,我想这没有一个明确的答案,不同人可以有不同的想法。下面说说我本人的理解。
- 作品尝试将用户进行的搜索过程看成是一个人机对话或者说是社会对话的过程:关键词的提出到搜索结果的反馈
- 从不同时期关键词的出现频率中可以反映出当前社会、时代的一些信息。
这里说的很抽象,可以结合后面的显示画面或者录像来理解。每当屏幕上出现了一个新的关键词,这表明某个地方正在有人搜索这个词,而随之出现的条目就是在对应搜索引擎上的结果了。当然,为了避免暴露个人隐私以及防止出现违反当地政策法规的词句出现,我们也自己实现了套山寨GFW...监控网络的具体地点也是保密的。
在展览现场,展示在观众面前的是一个高度近5米的大型投影荧幕。同时,每当有关键词出现,观众将感觉到有声音从对应文字出现的地方发出,这里采用了计算机实时语音合成(TTS)的手段将该关键词或者是搜索结果用中文女生朗读出来。由于加上了后期音频效果处理,以及TTS较为先进,合成的语音相对自然。
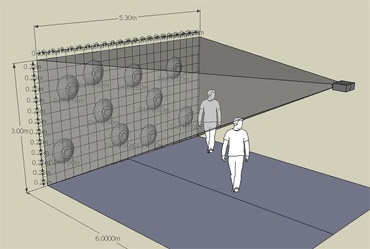
图:展区中作品的构架
上图给出了在展区中我们作品的大体布置情况,实际上,为了观众能更好的了解这个作品。在展厅中也准备了一台计算机,如果观众在该电脑上使用了Google都搜索引擎,对应的搜索关键词就会立刻被捕捉并且显示在荧幕上。
如果对作品的相关实现细节或者希望下载到其中开放的代码,可以关注文章后半部分。
图片、视频
这里给出该作品的一些画面以及我拍摄的录像。不过最佳的效果还是要在展厅中感受的。
Flv视频播放:

局部图案

全景图1
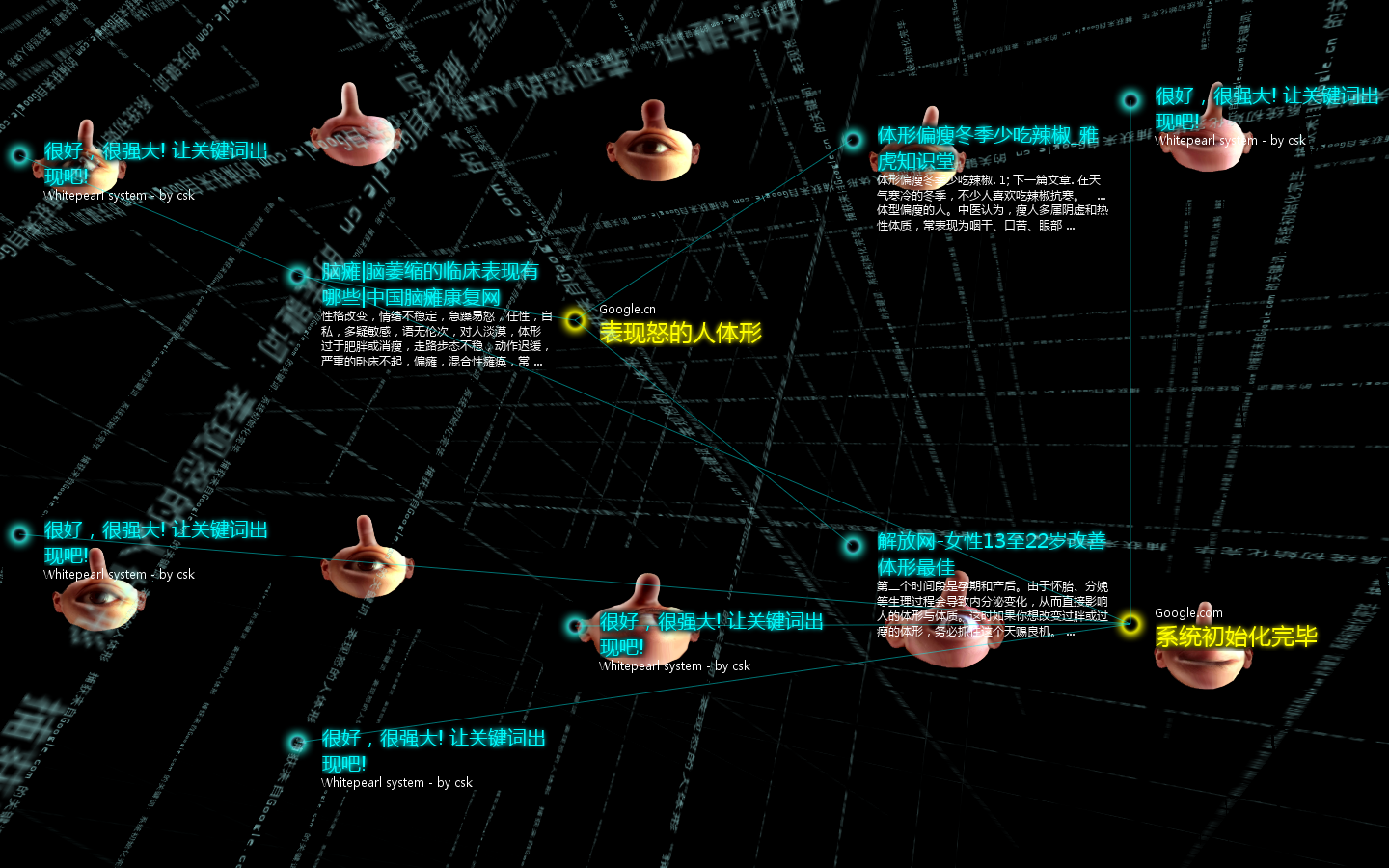
全景图2
参展感受
这次展览可以算是第一次我进入电子艺术甚至艺术领域,今后或许可以自封为艺术家了... 在经历了前期准备、布展、开展以及接受媒体采访这一系列事情后,我个人觉得最辛苦的还是布展阶段。可能目前没啥名气,布展完全就是自己动手做。不过等展品布置完毕,的确还是很有成就感的。
说实话,在布展完成前,我对这个展品自己都十分没有底。与之前作过的各类项目比较,虽然它的技术含量比以往相比没有高出的地方。不过不确定因素很多。
首先最大的问题是如何去捕捉网络中别人正在搜索的关键词?谁愿意冒着侵犯隐私的风险让我们来操作?同时捕捉的实现和采用的算法(要"鲁棒"且高效)是否管用?不过幸好在整个过程中找到的相关人士都很热心。后来看来基本上都是我们自己的担心。而实施起来都出奇的顺利。尤其当监控主机放到目标机房后,不需要任何调试就完美的工作了。
之所以说捕捉问题最令我担心,另外一个问题就是眼看10月中旬就正式开展了,而10月初几乎连要监控的网络都没有确定,并且对是否能够有效捕捉到我们的信息都不能确定。如果这个环节失败,那么作品就泡汤了。留下的估计就是被组委会责备的份了(应该也不会吧:-))
其次的问题是展会现场的视觉呈现实现,原本考虑直接用C++来编写整个视觉效果。不过因为在8月我已经正式工作了,可用时间比料想的少很多,就采用了一个正在被电子艺术家不断采用的基于Java的视觉框架Processing。这个在下一部份将具体介绍。不过说实话,在正式开始使用,以及看到他的源代码后,我本人对这个库颇有微词。主要的问题就是有点小儿科,效率也不够高。不过幸好他也支持OpenGL加速,所以从后来的效果上看,勉强达到了当时的需求。不过限于其功能的局限,例如不支持中文显示、没有可编程动画补间、filter效果等,无奈扩充了下他的代码。这部分代码(带缓存的中文字体显示、发光效果、可编程动画补间框架)将在文吅果需要可以任意使用,不过相关说明就不给出了,有bug就自己fix吧。
还有一个苛刻的问题就是要实现声音与画面方位的对应。如果让Speaker跟着画面动那绝对是扯淡,目前的解决办法是采用10个独立声道驱动的speaker阵列,并且利用人听觉的不敏感性来逼近这个效果。同时这10个声道可是要求能够独立的发音的。所谓“独立”,就是同时发音并且不同声道的音频信号是互不干扰的。而在展厅我们只采用一台普通的桌面PC来负责视频和音频的呈现。 为了降低硬件成本,后来采用了一块外置5.1声卡、2块2.1声卡的方案,这样正好凑成10个声道。这里也发现了Windows音频管理(或者说是DirectSound)的一个限制,只能同时驱动一块5.1卡,对于多出的5.1声卡标准的使用接口只会将其作为2.1声卡使用。同时多谢组委会的帮助,为我们购买了足够的音箱,使得这部分效果完美的实现了。(不过很多观众并没有发觉我们在音频上的做的文章)
实现上虽然之前顾虑很多,但总的来说都算顺利,合起来大致只花了1周多的时间就完成了所有的系统。真正累人的还是开展前的那一周,也就是布展阶段。原先认为只需要1天不到的时间将我们的系统(软件)安装到展厅的电脑,并且简单的修正下bug即可。可是没想到布展第一天,到了晚上我们只是仅仅让系统跑起来而已。那时的展厅用工地描述绝对不为过:没有任何光线、通风,没有座位供休息。其实这也不算什么,关键是投影仪、屏幕、speaker阵列均没有布置到,设备都不见影子。主要是因为施工队有限,大家都抢着找他们。同时没想到展厅的电脑使用了集成显卡,虽然处理器还算好,渲染效率没有很大变化。不过当正是部署起来,bug冒出一堆,后来无奈直接修改processing的代码。布展的第一天就在没有任何进展中度过了。由于展区在远在江湾体育馆,而公司在紫竹。回到住处已经凌晨一点。而后续几天实在不想特地请假,就每天下班后立刻冲到展区,继续布置。我现在还清晰的记得在我们安装speaker阵列的时候,那些音像不知多少次从墙上摔下来... 就这样持续了一周,到了正式开展当天,几乎已经精疲力尽,除了正式开展时有点兴奋劲外,别的时候想的只是要睡觉...
不过现在回忆起来那段时光还是很有趣的,这才是人生啊。虽然我不会以此为发展方向,不过了解了整个参展过程,同时接触到了这个领域不同的人,还是很有趣的一件事情。
在这里要十分感谢同是本作品创作者的高中同学何为,可以说是她把我带向这个领域。而在布展其间我gf也帮了不少忙,这里也十分感谢她。
当时也有人问起是否会参加今后的展览,我想应该还是会的。可以把此作为一项业余爱好来做。不过通过这次展览,我感觉到了人手和财力的不足。今后或许会多找些共同兴趣的人来组成一个工作室啥的。另外我也对国内喊了很多次,但都不见起色的Demo Scene抱有兴趣,话说现在,技术、人手应该都有了。不过这些都是后话了,还是把自己的主要事情做好吧。
构架与技术信息
整个系统细节上的问题太多,这里就主要以总体构架以及一些特点进行描述。
系统分布和组织
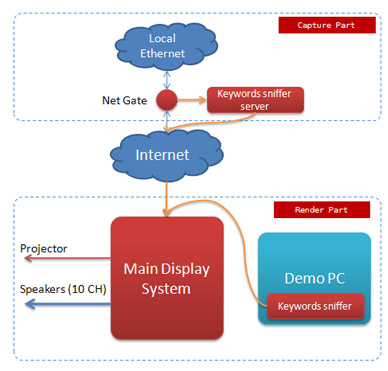
图:作品的实现构架
上图大体描述了目前这个作品的设计信息,其中我把Main Display System成为Whitepearl,而位于网络另一头负责关键词采集的sniffer server称为Black pearl。Sniffer server会将捕获到的关键词通过互联网实时得发送到展区的系统中。不过后来为了防止侵犯个人隐私以及出现不太和谐的词,就加了一层山寨GFW。
关键词捕捉
关键词捕捉说白了就是一套基于pcap的sniffer。在该作品中,这部分系统被称为Blackpearl。对于捕捉本身实际上就是查找HTTP request包的GET段的数据,同时要考虑不同环境下编码的问题。由于本系统时设计为类UNIX系统设计的,且默认编码环境为UTF-8。所以只需要考虑对GBK的转码问题。
如果对Black pearl感兴趣,可以在文末找到该系统的源代码。
视觉呈现
上文已经提到,这次以Processing作为个A7频渲染框架。不过鉴于Processing的诸多局限性,又对其进行了扩充。首先是增加了带位图缓存的支持中文字体显示的文本渲染类。支持wordwrap功能。这个类在文后给出了下载链接。Processing要实现文字显示,必须事先将每个字符提取并单独保存为位图格式(难道是受flash影响?)但是又做到十分简单,不但不是矢量化的,同时对于中文字体,由于要存储的字符过多,就直接OutofMemory Exception了。同时要在运行时灵活制定字体也十分麻烦。同时猜测他如此实现的唯一目的就是加快显示效率。但是看了他的实现后发现那样其实比直接的Textout还要慢!因此,干脆直接简简单单调用AWT渲染文字,并且缓存在位图。实践证明那样要比processing这种做法好太多。并且完全支持中文。这个类称为BufferedText。文末给出了他的代码。
而一些必要的特性,如可编程补间(对应Flash AS脚本中的Tween类),processing也一概没有。因此也花了些力气实现了他们。在今后会贴出整理后的代码。
音频呈现
音频部分是本作品的一大重点。除了选用比较优秀的TTS引擎外,就是要进行必要的效果处理,使得声音听上去不那么唐突。这里的实现是在MS SAPI完成对语音的合成后,利用fmod库进行reverb DSP过滤。reverb就直接采用了hall的配置。如果看了上面给出的视频,里面听到的声音就是最终的效果了。总体上说TTS对于中文的合成相当满意,不过对于英文部分,感觉是直接当拼音在拼读。为了能够和java层的视频部分联结,使用了jni做了层wrapper。
下载资源
1. Black pearl代码 ( 在Debian r4.0 以及 Ubuntu 8.04 上编译并测试通过 )
http://www.csksoft.net/data/legacyftp/Products/code_and_lib/black_pearl.7z
2. BufferedText 代码
http://www.csksoft.net/data/legacyftp/Products/code_and_lib/BufferedText.java